How I’d Become a Data Engineer If I Had to Start Over
Yesterday evening, I went to play football with my guys. Nonso; one of the guys I usually play with pulled me aside and said:
Jindu, I heard you’re a data engineer. I’m thinking of moving into the field, how would you advise on what to learn to land a job?
He’s a cybersecurity engineer, so not a beginner by any means. Very technical. Understands systems. Smart guy.
But the question still made me think.
People jump in and start collecting tools: Python, SQL, Spark, Airflow, without really understanding what they’re doing. After a while, it becomes noise. No impact.
So I didn’t want to give him that kind of answer. I wanted something simpler. Something practical.
I asked myself:
“If I had to do this all over again, what would I do?”
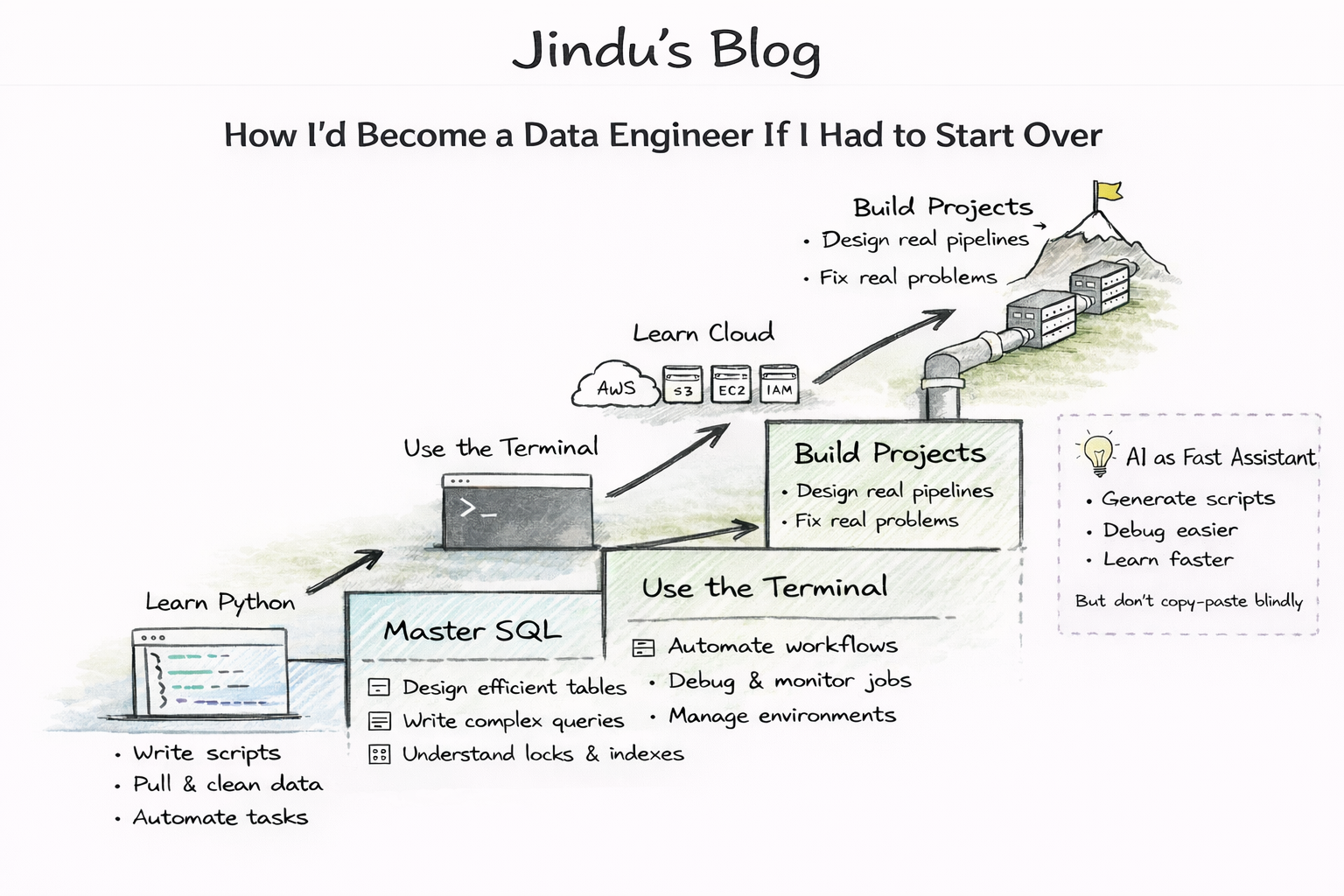
I Would Start with Python
I wouldn’t rush. I wouldn’t try to finish Python in two weeks. I’d take my time to really learn how to use it to do things:
- Writing scripts that actually solve problems
- Working with files like CSV and JSON
- Pulling data from APIs (and navigating folders/paths confidently)
- Automating small, boring tasks
At the most basic level, data engineering is really just this:
Move data. Transform data. Automate it.
Python helps with most of that.
Then Next Would Be SQL
Strong fundamentals matter.
Before anything else, I’d make sure I actually understand how databases work, not just writing queries, but things like creating tables properly, what causes locks, how indexes improve performance, and why good table design makes everything easier down the line.
Then I’d focus on how data behaves when you query it:
- How do you join tables without accidentally duplicating rows?
- When should you use window functions, and what problems do they actually solve?
- How do you write queries that still perform when the data gets big?
Because the truth is: things work fine with small data. But at scale, bad queries become very obvious. Things get slow, pipelines fail, and costs go up.
Once you get comfortable at this level, you’re thinking like someone who understands data.
And I wouldn’t stick to just one system. I’d get exposure to PostgreSQL, MySQL, SQL Server, and Redshift too.
Because no matter how modern things get, if you can’t work with data in a database, you really can’t do much.
I’d Learn the Terminal (Even though it is boring)
This is one of those things people avoid because it feels boring, but I’ve found that being comfortable with the terminal drastically speeds up your work.
I’d get comfortable with:
- Chaining commands together to automate workflows
- Scheduling jobs (cron jobs, background processes)
- Debugging when scripts fail (logs, permissions, paths)
- Working with environment variables and configs
Then I’d Pick Up Cloud But Keep It Practical
At this point, I’d start with AWS. I wouldn’t try to learn 20 services, just the ones that matter early on:
- S3 (to store data)
- EC2 (to run things)
- IAM (to control access)
- DynamoDB (for NoSQL)
And most importantly, I’d use and connect them. Upload something, process it, save the output.
That flow matters more than memorizing services you’re not using.
Finally, I’d Build Projects (“Skin in the Game”)
This is the part that actually makes you a data engineer: projects.
I’d build simple pipelines that do the full loop:
- Pull data from somewhere
- Clean it
- Store it
- Schedule it
And I’d fix the errors when things break because fixing broken pipelines teaches you more than any course ever will.
If you’re looking for practical, project based tutorials, check out @codewithYU on YouTube. His content makes it easier to see how things work in real scenarios, and it’s a solid place to get project ideas.
AI
Then there’s AI; the elephant in the room.
When used well, it can speed things up a lot. You can debug faster, generate scripts, and unblock yourself quickly when you’re stuck. It’s like having a very fast assistant while you’re learning. It honestly reminds me of JARVIS from Iron Man.
But there’s a catch.
If you rely on it without understanding what’s going on, you’ll fall into the trap of copying and pasting code you don’t actually understand. And that slows your growth more than it helps.
The way to use AI is simple:
- Let it guide you, not replace your thinking
- Ask it to explain things, not just generate them
- Always take time to understand the output before moving on
Because in the long run, your value doesn’t come from generating code, it comes from understanding systems. AI should help you get there faster, not skip the process entirely.
Final Thought
That random conversation after a football game stuck with me, because it reminded me how easy it is to overcomplicate this field.
At its core, data engineering isn’t as complex as people make it seem.
It’s just this:
Take data from somewhere, make it useful, and move it somewhere else reliably. That’s it, everything else is just tools.
And if you can truly understand that flow, you’re already off to a good start.
About the author
I help teams in fintech, Banking & Finance, and energy build and scale data systems that work in production from pipelines and analytics to models that support real decisions. This blog is where I share practical lessons from that work.
- Say hi: Connect on LinkedIn: I'm always open to conversations about data, analytics, and engineering.
- Consulting: I take on selective work helping organizations build and scale data platforms in Africa and similar markets. If you need a partner on architecture, delivery, or analytics, email me or visit the contact page.